

三种 InlineHook 对比
InlineHook 有三类,对比如下:
| x86 InlineHook | ret | jmp reg | jmp offset |
|---|---|---|---|
| 影响字节数 | 6 字节 | 7 字节 | 5 字节 |
| 影响寄存器 | 无 | 影响一个寄存器的值 | 无 |
| 通用性 | 通用 | 通用 | 通用 |
| x64 InlineHook | ret | jmp reg | jmp offset |
|---|---|---|---|
| 影响字节数 | 14 字节 | 12 字节 | 6 字节 |
| 影响寄存器 | 无 | 影响一个寄存器的值 | 无 |
| 通用性 | 通用 | 通用 | 寻址范围低 |
通常情况下 x64 使用 ret 方式,x86 使用 jmp offset 方式即可
InlineHook:ret
x86 6 字节
原理介绍:
push Address
ret
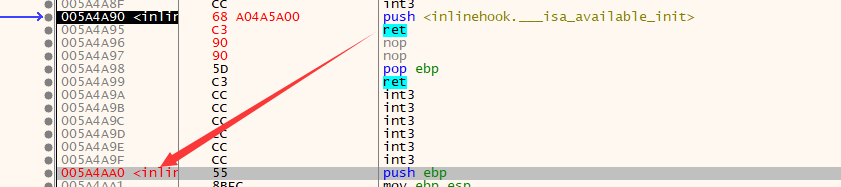
硬编码:
Byte[6] = {0x68,0,0,0,0,0xC3} // 中间4位是地址
x64 14 字节
原理介绍:
push LowAddress;
mov dword ptr ss:[rsp+4], HighAddress;
ret
PUSH 指令最多支持 32 位立即数,为了不改变寄存器,这里需要通过 push 提高栈顶,然后通过 mov 填充完整地址,再通过 ret 跳转
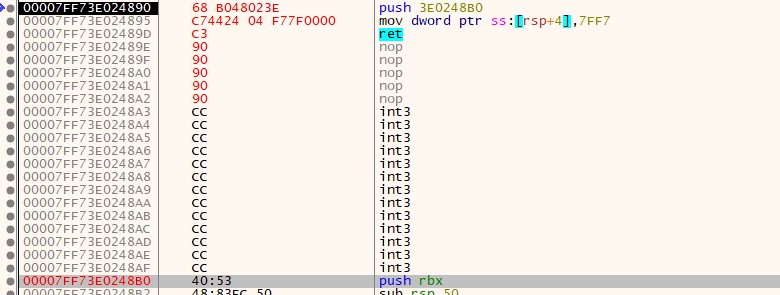
硬编码:
Byte[14] = {0x68,0,0,0,0,0xC7,0x44,0x24,0x04,0,0,0,0,0xC3} // 前4位是低位地址,后4位是高位地址
InlineHook:jmp reg
x86 7 字节
原理介绍:
mov eax, Address;
jmp eax;
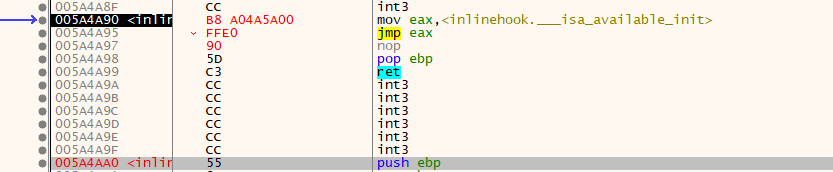
硬编码:
Byte[7] = {0xB8,0,0,0,0,0xFF,0xE0}; // 中间4位是地址
x64 12 字节
原理介绍:
mov rax, Address;
jmp rax;
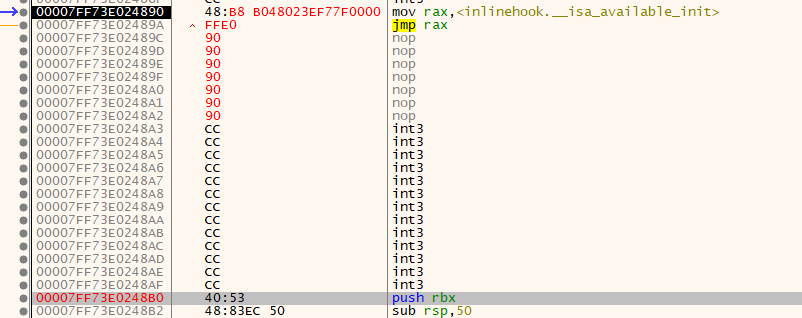
硬编码:
Byte[12] = {0x48,0xb8,0,0,0,0,0,0,0,0,0xFF,0xE0} // 中间8位是地址
InlineHook:jmp offset
x86 5 字节
原理介绍:
E9 跳转指令后面的 4 字节是与当前地址的偏移:Offset = 目标地址 - 当前地址 - 指令长度 5
jmp offset
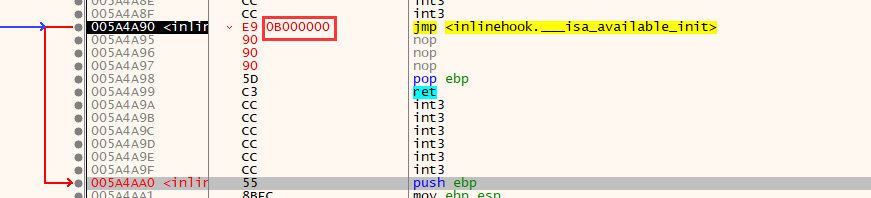
硬编码:
Byte[5] = {0xE9,0,0,0,0} // 中间4位是地址
x64 6 字节
原理介绍:
64 位可以使用 rip 进行寻址,64 位进程寻址能力变成了 8 字节,然而 64 位汇编中所有的跳转直接寻址只支持 4 字节。
jmp qword ptr [rip + offset];
这里会从 rip 开始计算偏移取 8 字节地址,如图,这里设置的偏移是 9,于是就在地址 =当前地址 + 指令长度 6 + 9,也就是第二个红框处取地址进行跳转
因为寻址仅支持 4 字节,最大寻址范围 2GB,在 64 位程序内存中很容易就超出这个范围,这个方法能用,但不通用
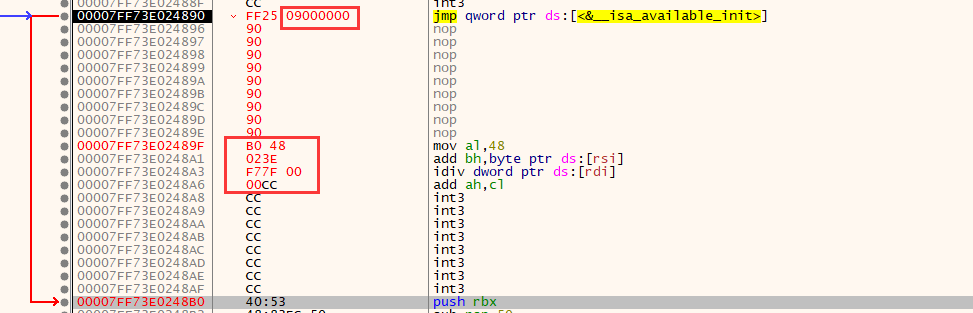
硬编码:
Byte[6] = {0xFF,0x25,0,0,0,0} // 后面4位是地址所在地址距离当前位置的偏移