

AFL 复现 Crash 样本
本段选自 Fuzzing 101
下载xpdf:
wget https://dl.xpdfreader.com/old/xpdf-3.02.tar.gz
tar -xvzf xpdf-3.02.tar.gz
使用AFL编译器插桩编译:AFL通过对编译器进行封装来完成插桩操作,需要指定编译器
常用的编译器:
- afl-clang-fast
- afl-clang-lto(编译的同时会收集程序自身的token加速编译)
# CC=afl-clang-lto CXX=afl-clang-lto++ ./configure --prefix=/root/work/xpdf-3.02/install
CC=afl-clang-fast CXX=afl-clang-fast++ ./configure --prefix=/root/work/xpdf-3.02/install
AFL_USE_ASAN=1 make
make install
环境变量:AFL_USE_ASAN=1,make的时候会调用编译器,会对环境变量进行解析,不需要指定ASAN选项,指定了环境变量,,编译器就会开启(方便的做法)
fuzz过程需要语料库,不需要太全太细致,好的语料库应该满足以下条件:
- 针对单个样本足够小,
- 能覆盖尽可能多的功能
- 对于样本集,要覆盖到已知的全部功能,覆盖越多效果越好
开源的语料库:
wget https://github.com/mozilla/pdf.js-sample-files/raw/master/helloworld.pdf
wget http://www.africau.edu/images/default/sample.pdf
wget https://www.melbpc.org.au/wp-content/uploads/2017/10/small-example-pdf-file.pdf
使用afl开始fuzz:
afl-fuzz -i samples/ -o output/ xpdf-3.02/install/bin/pdftotext @@ demo_out
afl的选项:
-i:语料库目录
-o:输出目录
二进制程序
@@:输入的文件名(占位符)(输入一种是通过标准输入,一种是通过读文件)
demo_out:输出文件,随便命名
-m none:对于64位,默认内存太小,可能会过不了afl初始化检测,遇到了再加
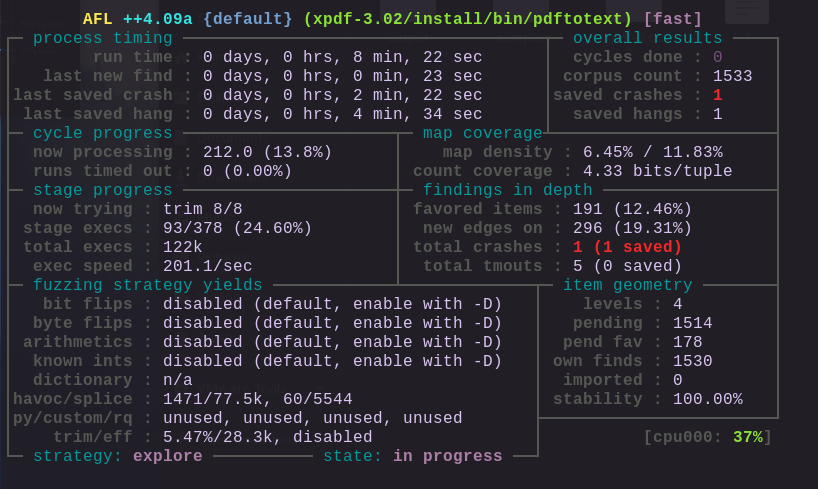
没一会就出现Crash样本了
漏洞分析
漏洞细节描述:被构造的文件会导致Parser.cc文件中的Parser::getObj()函数出现无限递归,可以利用此进行DOS攻击
在gdb下使用Crash样本去运行,成功触发奔溃,重新运行几轮循环,查看调用堆栈bt:

跟进分析
首先是main函数,这里首先初始化了文本输出,然后调用了displayPages函数,用于显示文本内容
int main(int argc, char *argv[]) {
PDFDoc *doc;
GString *fileName;
GString *textFileName;
GString *ownerPW, *userPW;
TextOutputDev *textOut;
FILE *f;
UnicodeMap *uMap;
Object info;
GBool ok;
char *p;
int exitCode;
...
// write text file
textOut = new TextOutputDev(textFileName->getCString(),
physLayout, rawOrder, htmlMeta);
if (textOut->isOk()) {
doc->displayPages(textOut, firstPage, lastPage, 72, 72, 0,
gFalse, gTrue, gFalse);
} else {
delete textOut;
exitCode = 2;
goto err3;
}
...
return exitCode;
}
接下来按页进行显示,对每一页进行displayPage调用:
void PDFDoc::displayPages(OutputDev *out, int firstPage, int lastPage,
double hDPI, double vDPI, int rotate,
GBool useMediaBox, GBool crop, GBool printing,
GBool (*abortCheckCbk)(void *data),
void *abortCheckCbkData) {
int page;
for (page = firstPage; page <= lastPage; ++page) {
displayPage(out, page, hDPI, vDPI, rotate, useMediaBox, crop, printing,
abortCheckCbk, abortCheckCbkData);
}
}
这里是通过catalog->getPage来获取对应的页调用display方法显示:
void PDFDoc::displayPage(OutputDev *out, int page,
double hDPI, double vDPI, int rotate,
GBool useMediaBox, GBool crop, GBool printing,
GBool (*abortCheckCbk)(void *data),
void *abortCheckCbkData) {
if (globalParams->getPrintCommands()) {
printf("***** page %d *****\n", page);
}
catalog->getPage(page)->display(out, hDPI, vDPI,
rotate, useMediaBox, crop, printing, catalog,
abortCheckCbk, abortCheckCbkData);
}
接下来是调用displaySlice:
void Page::display(OutputDev *out, double hDPI, double vDPI,
int rotate, GBool useMediaBox, GBool crop,
GBool printing, Catalog *catalog,
GBool (*abortCheckCbk)(void *data),
void *abortCheckCbkData) {
displaySlice(out, hDPI, vDPI, rotate, useMediaBox, crop,
-1, -1, -1, -1, printing, catalog,
abortCheckCbk, abortCheckCbkData);
}
这里开始准备进入循环:
void Page::displaySlice(OutputDev *out, double hDPI, double vDPI,
int rotate, GBool useMediaBox, GBool crop,
int sliceX, int sliceY, int sliceW, int sliceH,
GBool printing, Catalog *catalog,
GBool (*abortCheckCbk)(void *data),
void *abortCheckCbkData) {
#ifndef PDF_PARSER_ONLY
PDFRectangle *mediaBox, *cropBox;
PDFRectangle box;
Gfx *gfx;
Object obj;
Annots *annotList;
Dict *acroForm;
int i;
...
gfx = new Gfx(xref, out, num, attrs->getResourceDict(),
hDPI, vDPI, &box, crop ? cropBox : (PDFRectangle *)NULL,
rotate, abortCheckCbk, abortCheckCbkData);
contents.fetch(xref, &obj);
...
#endif
}
这里前面做了一些检查,这里的contents.fetch(xref, &obj),就是开始解析内容了
这里的contents,是一个objRef类型的对象,ref二元组为(num=7, gen=0)
pwndbg> p contents
$1 = {
type = objRef,
{
booln = 7,
intg = 7,
real = 3.4584595208887258e-323,
string = 0x7,
name = 0x7 <error: Cannot access memory at address 0x7>,
array = 0x7,
dict = 0x7,
stream = 0x7,
ref = {
num = 7,
gen = 0
},
cmd = 0x7 <error: Cannot access memory at address 0x7>
}
}
接下来的流程:这里传入了ref.num和ref.gen:
Object *Object::fetch(XRef *xref, Object *obj)
{
return (type == objRef && xref) ? xref->fetch(ref.num, ref.gen, obj) : copy(obj);
}
这里的num=7,gen=0,来自上面的传参,接下来要去解析满足这个二元组的对象
Object *XRef::fetch(int num, int gen, Object *obj)
{
XRefEntry *e;
Parser *parser;
Object obj1, obj2, obj3;
...
e = &entries[num];
switch (e->type)
{
case xrefEntryUncompressed:
if (e->gen != gen)
{
goto err;
}
obj1.initNull();
parser = new Parser(this,
new Lexer(this,
str->makeSubStream(start + e->offset, gFalse, 0, &obj1)),
gTrue);
parser->getObj(&obj1);
parser->getObj(&obj2);
parser->getObj(&obj3);
if (!obj1.isInt() || obj1.getInt() != num ||
!obj2.isInt() || obj2.getInt() != gen ||
!obj3.isCmd("obj"))
{
obj1.free();
obj2.free();
obj3.free();
delete parser;
goto err;
}
parser->getObj(obj, encrypted ? fileKey : (Guchar *)NULL,
encAlgorithm, keyLength, num, gen);
obj1.free();
obj2.free();
obj3.free();
delete parser;
break;
...
return obj;
err:
return obj->initNull();
}
这里调用的parser->getObj(obj, encrypted ? fileKey : (Guchar *)NULL,encAlgorithm, keyLength, num, gen);把刚刚的num和gen传入了,正如推测,就是7和0
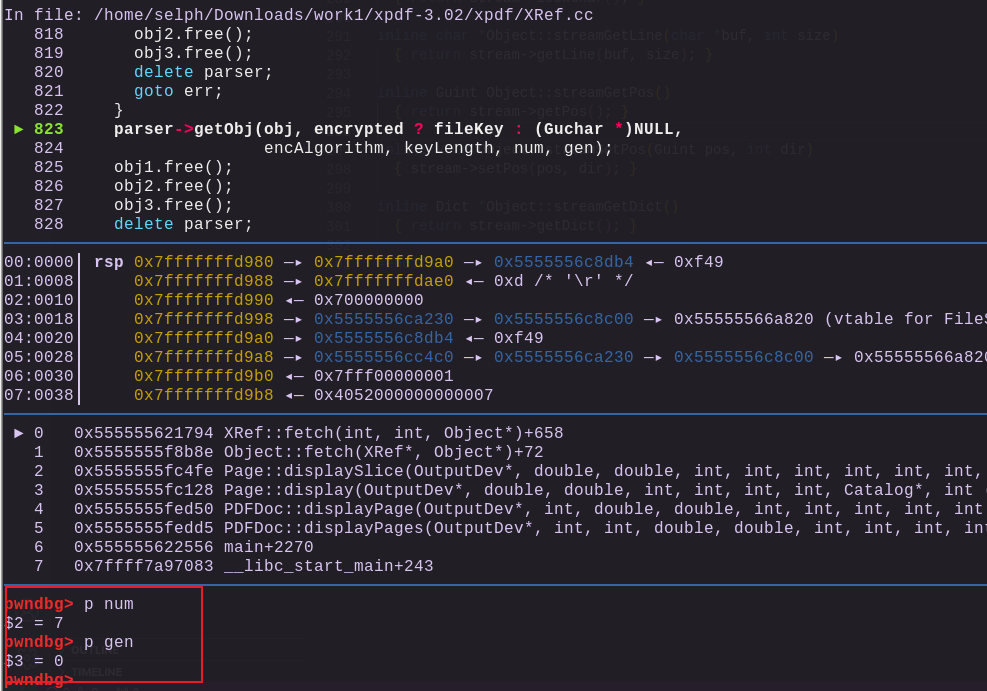
于是,这里就造成了递归调用(因为上一次getObj就是向num=7,gen=0去获取对象的,这里又再次向这个参数获取对象)
再次回顾一下无限递归的调用堆栈现场:
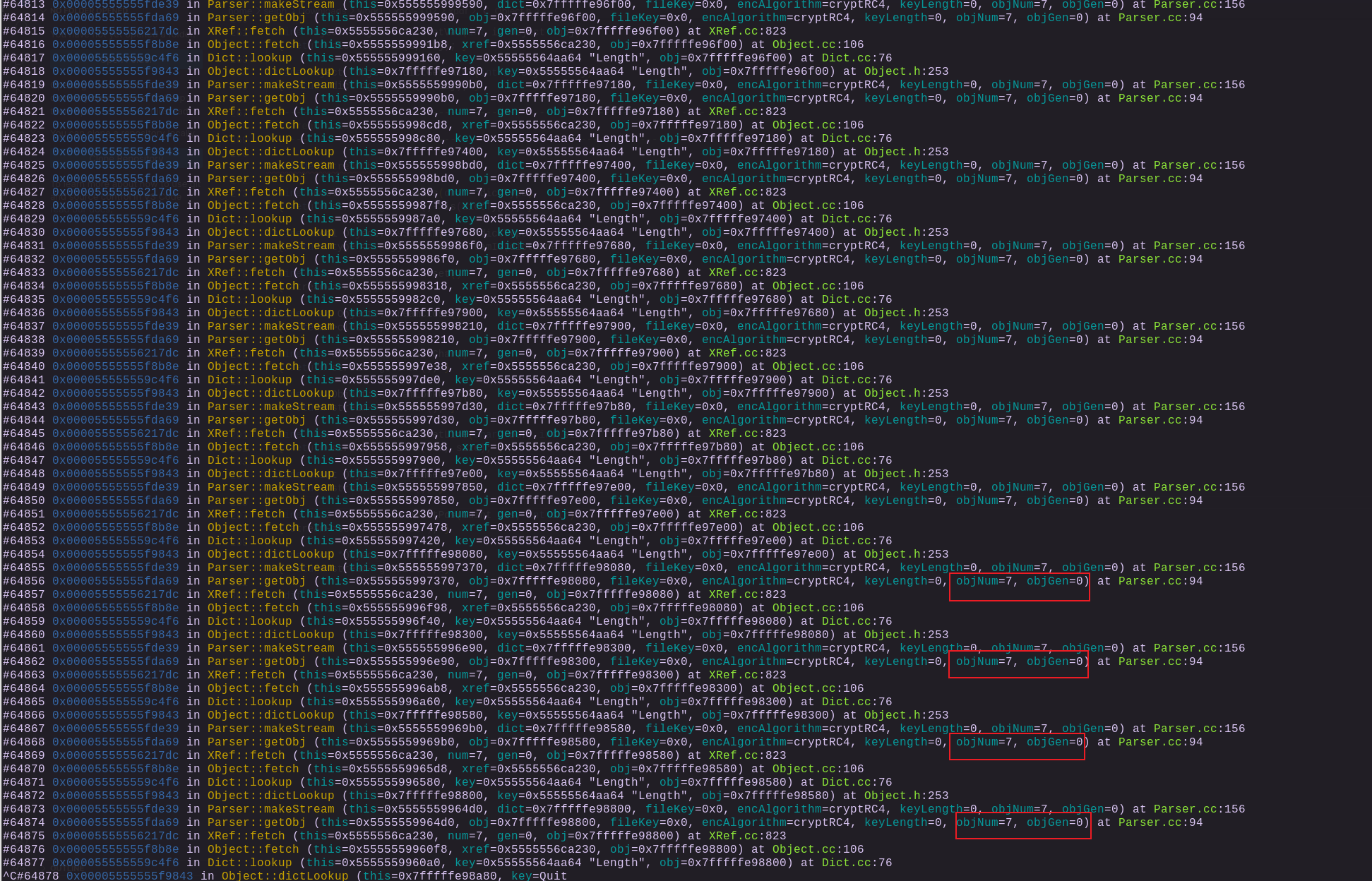
确实是不断在解析7,0的对象
关于样本
关于pdf格式文件的解析流程,pdf文件有很多节点,节点保存对象的信息,可以是流,可以说文本,可以是图片
如下是一个正常的pdf内容:
3 0 obj
<<
/Type /Page
/Parent 2 0 R
/Resources <<
/Font <<
/F1 4 0 R
>>
>>
/Contents 5 0 R
>>
endobj
4 0 obj
<<
/Type /Font
/Subtype /Type1
/BaseFont /Times-Roman
>>
endobj
这里3号对象:3 0 obj中使用了字体,字体来源于4 0 R,这里的4 0是对象序号,R表示是引用,所以解析的时候就会去寻找4 0 obj对象
我们样本中我发现了这么一行:
7 0 obj
<</Length 7 0 R/Filter /FlateDecode>>
stream
x��P�N�0
���H�jl7N�b
这里的7 0 obj对象,有个属性是Length,刚刚在跟踪源码的时候,也见到了去寻找Length属性的环节,这里的Length属性是个引用,所以就会向着该引用指向的对象去解析
然而该对象引用指向的对象正好是自己,从而造成了无限递归的漏洞
漏洞修复
分析参考了参考资料[1],师傅分析的很详细,但是有问题,这里造成漏洞的成因是Length对象自己引用了自己,解析引用导致无限递归,该对象不见得就是整数类型,是引用类型也是正常的
所以修复方法是,限制搜索引用的层数,也就是当搜索太多层引用找不到目标对象,就不找了,认为这里有问题,然后进行问题处理
看看官方的漏洞修复:
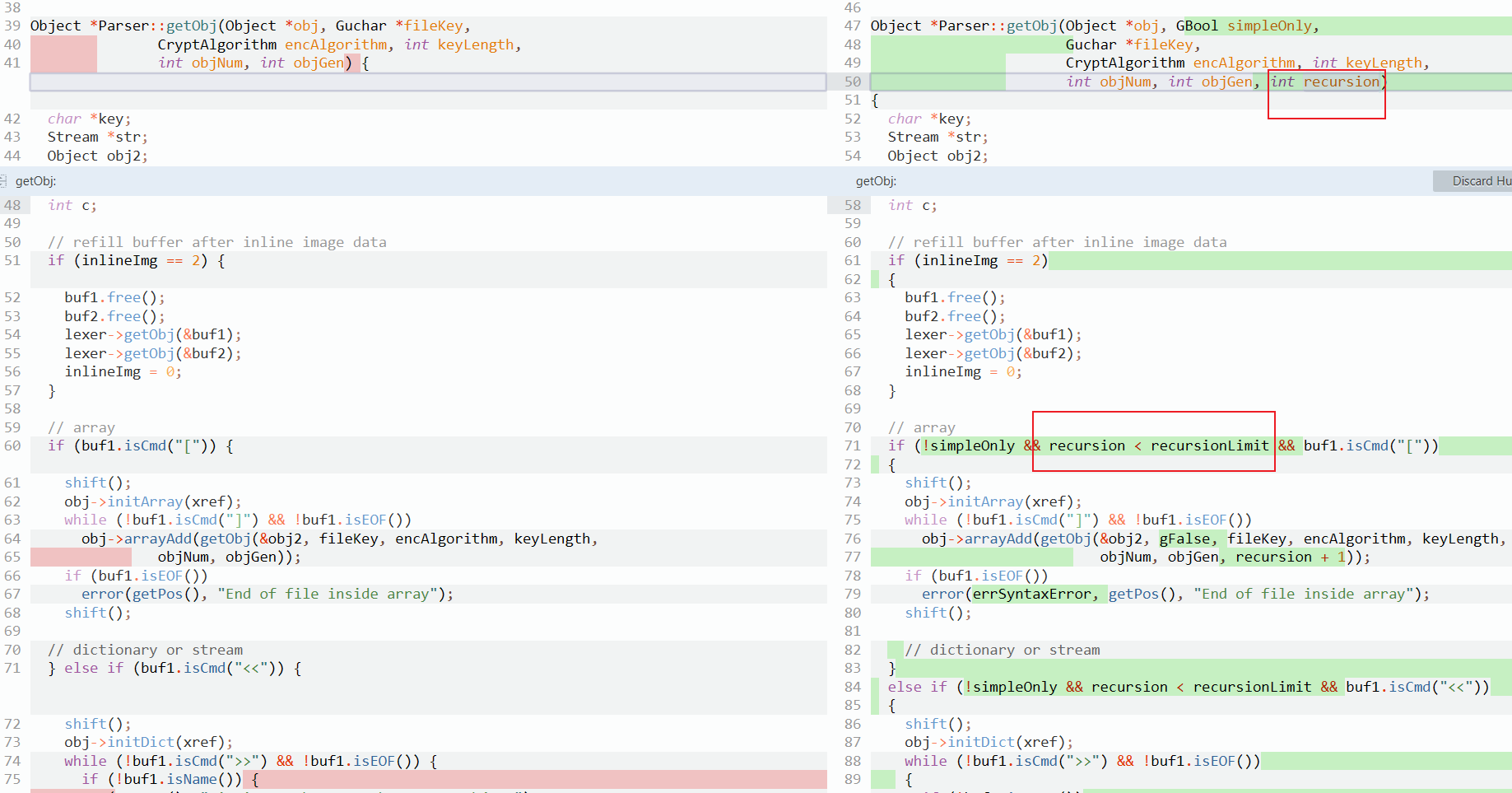
为该函数添加了个参数recursion,在下面的判断中判断递归层数,超过上限,就不再继续执行
参考资料
- [0] Fuzzing101/Exercise 1/Readme.md at main · antonio-morales/Fuzzing101 (github.com)
- [1] Fuzzing101-1:Xpdf (ruanx.net)