

学习环境:Windows 10 20H2 + Visual Studio 2019
参考书籍:《C++反汇编与逆向分析技术揭秘》
整数类型
C++提供的整数类型:short、int、long
整数类型又分为有符号和无符号
无符号整数
表示范围:0x0~0xFFFFFFFF
Windows的内存使用小端序进行存放数据,小端序就是低端数据放在低端内存,以字节为单位存放
有符号整数
最高位表示符号位,表示范围比无符号位少了一位:0x80000000~0x7FFFFFFF
正数区间:0x00000000~0x7FFFFFFF
负数区间:0x80000000~0xFFFFFFFF(0x80000000规定为0x80000001-1)所以负数的最小值比正数多1个
对于任何有符号整数,都是以补码形式存放的,因为计算机只能进行加法
补码的规则是:用0减去这个数的绝对值,或者说是这个数取反+1
对于任何4字节的数值x,都有x+x(反) = 0xFFFFFFFF,故x+x(反)+1=0(进位丢失),即:0-x = x(反)+1
通过补码转换,就能把负数转换成加法运算了
浮点数类型
在C++中,通过浮点类型进行存储实数:float(4字节)、double(8字节)
正数类型会将十进制直接转换成二进制存入内存中,浮点类型则会将浮点小数转换成二进制码重新编码再进行存储
将浮点数强转位整数时,会直接舍弃小数部分
浮点数的操作通常不会用到通用寄存器,而是浮点协处理器的浮点寄存器
VC++6.0使用浮点前需要对浮点寄存器进行初始化才能正常运行(在代码中任意位置定义一个浮点类型的变量即可对浮点寄存器进行初始化)
浮点数的编码方式
浮点数编码转换采用IEEE规定的编码标准,float和double两种类型的转换原理相同,但表示范围不一样,编码方式有些区别
浮点数分为三部分:符号、指数、尾数。
floag类型的IEEE编码
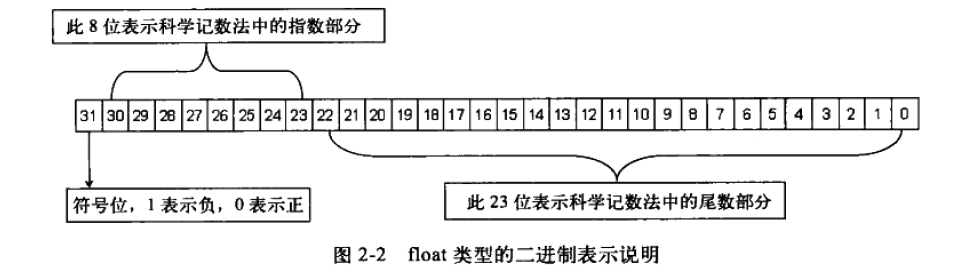
float类型占用4字节,最高位表示符号位,接下来8位表示指数位,剩下的是尾数
转换过程如下:以11.75为例
-
将十进制转换成二进制:1011.11
-
将二进制按科学计数法表示:1.01111
科学计数法:小数点向左移动,直到最高位的1为止,每次移动指数位+1
-
指数位:3 + 127
IEEE编码规定,指数位01111111(127)为0
-
得到各位的值:
- 符号位:0(正数)
- 指数位:130(1000 0010)
- 尾数位:0111 1000 0000 0000 0000 000
-
拼接各位:0100 0001 0011 1100 0000 0000 0000 0000,即:0x413c0000
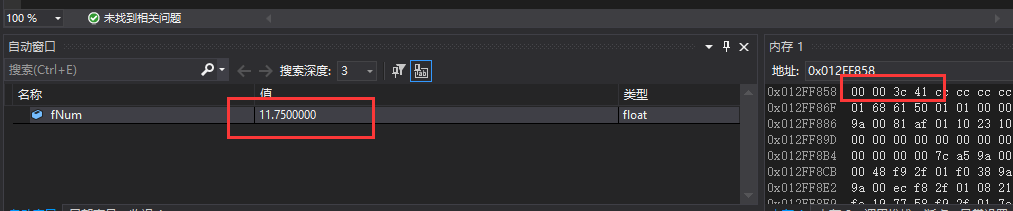
由于尾数只有23位,若实际数值超出了23位就会截断,所以会出现误差
double类型的IEEE编码
double转换过程同float,只是每位的长度变了
| 符号位:1位 | 指数位:11位 | 尾数位:52位 |
|---|---|---|
| 0表示正,1表示负 | 1023表示0 | 任意 |
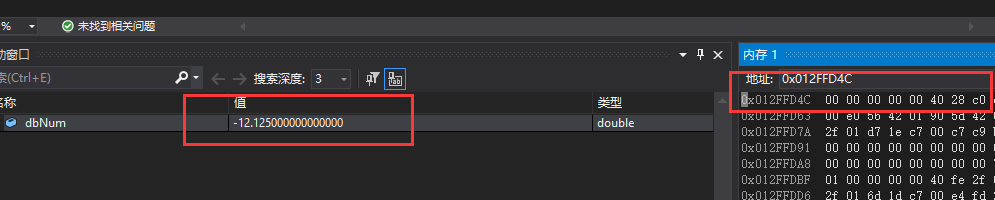
举例:-12.125(科学计数法:1.100001,指数位:3)
- 符号位:1
- 指数位:3+1023 = 1026(1000000010)
- 尾数位:100001 0000....
拼接后:1100 0000 0010 1000 0100 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000
换成十六进制就是:0xc0284000000000000,测试结果如下:
基本的浮点数指令
浮点数不使用通用寄存器,使用浮点数寄存器,浮点数寄存器由ST(0)~ST(7)共8个栈空间构成
最先使用的是ST(0),不能跳过ST(0)使用ST(1),ST(0)存在数据的时候,新的数据会存入到ST(1)
浮点寄存器使用的就是压栈、出栈的过程。
常用指令:

字符和字符串
C++中,字符串以\0结尾
字符的编码
C++中有两种:ASCII和Unicode,后者是前者的升级编码格式
两种编码都可以表示中文:
- ASCII使用GB2132-80编码,两个字节表示一个汉字,保存了6763个常用汉字
- Unicode使用UCS-2编码,可存储65536个字符
字符串的存储方式
ASCII:
Unicode:

布尔类型
真:≠0
假:0
地址、指针和引用类型
地址:变量才有地址,常量没有地址(const声明的伪常量不算)
指针:指针的值是地址(TYPE*)
引用:引用表示一个变量的别名(TYPE&)
指针和地址的区别
不同点:
| 指针 | 地址 |
|---|---|
| 变量,保存标量地址 | 常量,内存标号 |
| 可修改,再次保存其他变量地址 | 不可修改 |
| 可以对其执行取地址得到地址 | 不可执行取地址 |
| 包含对保存地址的解释信息 | 仅仅有地址值无法解释数据 |
要用指针类型保存了地址之后,才能读取地址的内容
相同点
| 指针 | 地址 |
|---|---|
| 取出指向地址内存中的数据 | 取出地址对应内存中的数据 |
| 对地址偏移后,取数据 | 偏移后取数据,自身不变 |
| 求两个地址的差 | 求两个地址的差 |
各类型指针的工作方式
指针对地址的解释取决于指针的类型
指针类型只支持加减法运算
例如:int类型指针的值 +1,实际上该指针地址值 + 4,因为这个+1指的是再+1个这样的变量,int类型是四字节,所以+4
两个指针相加是没有意义的,减法操作只支持同类型指针相减
引用
引用类型是为了简化指针操作而封装出来的,在反汇编下,引用类型不存在,就是指针,测试分析如下:
实验:引用类型分析
测试代码
#include <stdio.h>
void Add0(int& num) {
num++;
}
void Add1(int* num) {
(*num)++;
}
int main() {
int a = 0x10;
Add0(a);
Add1(&a);
printf("%x",a);
return 0;
}
分析引用类型反汇编
把变量地址取出来,然后压栈进入函数
Add0(a);
00A74879 lea eax,[a]
00A7487C push eax
00A7487D call Add0 (0A713B6h)
00A74882 add esp,4
函数:把变量的值取出来,使用变量的值找到数据,修改数据,然后把数据放回变量的值指向的地址
00A71DF8 mov eax,dword ptr [num]
00A71DFB mov ecx,dword ptr [eax]
00A71DFD add ecx,1
00A71E00 mov edx,dword ptr [num]
00A71E03 mov dword ptr [edx],ecx
分析指针类型反汇编
把变量地址取出来,然后压栈进入函数,和引用类型一模一样
Add1(&a);
00A74885 lea eax,[a]
00A74888 push eax
00A74889 call Add1 (0A713BBh)
00A7488E add esp,4
函数:和引用类型是一样的过程
00A72E78 mov eax,dword ptr [num]
00A72E7B mov ecx,dword ptr [eax]
00A72E7D add ecx,1
00A72E80 mov edx,dword ptr [num]
00A72E83 mov dword ptr [edx],ecx
常量类型
常量是一个固定的值,在内存中不可修改(位于PE文件的.rdata段),常量在程序运行前就存在了
常量的定义
常量定义方法:
-
使用
#define宏进行定义,在编译的时候,宏所对应的名称会被直接替换成值 -
使用
const关键字进行定义
这两种方法的区别:
#define定义的常量是真常量,const定义的常量是假常量,是可以更改的
使用const定义的常量实际上还是个变量,只是在编译器内进行检查,如果有修改就报错
| #define | const |
|---|---|
| 编译期间查找替换 | 编译期间检查const修饰的变量是否被修改 |
| 由系统判断是否被修改 | 由编译器限制修改 |
| 字符串定义在文件的只读数据区,数据常量编译位立即数寻址,是二进制代码的一部分 | 根据作用域决定所在的内存位置和属性 |
这两者类型再链接生成二进制文件后就不存在了,二进制编码里没有这两种类型的存在
实验:修改 const 常量
测试代码
#include <stdio.h>
int main() {
const int a = 0x10;
int* pInt0 = (int*)&a;
(*pInt0)++;
int pInt1 = a;
printf("a = %x\npInt0 = %x\npInt1=%x\n",a,*pInt0,pInt1);
return 0;
}
反汇编分析
编译器将const常量的值,使用硬编码替换了所有该常量名出现的地方,就像#define一样
不同的的是const常量是被修饰为常量的变量,在内存空间的存储和变量是一样的,可以直接获取该常量的地址,对地址的值进行修改
const int a = 0x10;
00D01892 mov dword ptr [a],10h ;给变量a赋值
int* pInt0 = (int*)&a
00D01899 lea eax,[a] ;获取变量a地址
00D0189C mov dword ptr [pInt0],eax ;将变量a地址给指针变量pInt0
(*pInt0)++;
00D0189F mov eax,dword ptr [pInt0] ;获取pInt0的值,是个地址
00D018A2 mov ecx,dword ptr [eax] ;获取该地址里的值,也就是变量a的地址
00D018A4 add ecx,1 ;这个值+1
00D018A7 mov edx,dword ptr [pInt0] ;将这个值放回变量a的地址
00D018AA mov dword ptr [edx],ecx
int pInt1 = a;
00D018AC mov dword ptr [pInt1],10h ;将硬编码的0x10给变量pInt1
printf("a = %x\npInt0 = %x\npInt1=%x\n",a,*pInt0,pInt1);
00D018B3 mov eax,dword ptr [pInt1] ;获取变量pInt1的值
00D018B6 push eax ;入栈pInt1的值
00D018B7 mov ecx,dword ptr [pInt0] ;获取变量pInt0的值,入栈
00D018BA mov edx,dword ptr [ecx]
00D018BC push edx
00D018BD push 10h ;直接入栈一个常数
00D018BF push offset string "a = %x\npInt0 = %x\npInt1=%x\n" (0D07B30h)
00D018C4 call _printf (0D010CDh)
00D018C9 add esp,10h
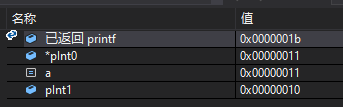
运行截图
const常量 a 的值被修改成了0x11
小结
计算机的工作,归根到底就是,输入->处理->输出,这个过程;而数据是处理的对象,逆向分析最重要的是要正确观察数据,有两点:
-
在哪里?
要确定数据的存储位置,对于内存中的数据,要查看地址,有了地址就可以得到内存属性:可读、可写、可执行,从而可以判断这段数据是变量(读写)?常量(只读)?代码(可执行)?
继续观察进程内存布局,如栈区、堆区、全局区、代码区等,从而可以知道数据的作用域。
-
如何解释?
知道了数据在哪里,就需要知道数据是什么