

本篇对应书籍第十二章的内容
本篇内容介绍了基于中断的系统调用的实现,并使用系统调用实现了printf函数以及内存管理相关的malloc和free函数。
本篇难点:
- 理解中断机制执行流程,理解系统调用执行流程
- 理解arena内存块的分配,以及内存的释放
Linux 系统调用浅析
系统调用用来限制用户程序的能力的,需要涉及关键部位的操作,必须通过操作系统进行执行,系统提供功能给用户程序使用,这就叫系统调用
Linux 通过中断门实现调用,占用一个中断向量号,0x80,通过 eax 传递子功能号参数
Linux 系统调用使用寄存器传递参数(主要是寄存器传参速度快,步骤少),eax 保存子功能号、ebx 保存第1个参数,ecx 保存第2个参数,edx 保存第3个参数,esi 保存第4个参数,edi 保存第5个参数
这里参考过气的_syscall宏来实现我们的系统调用
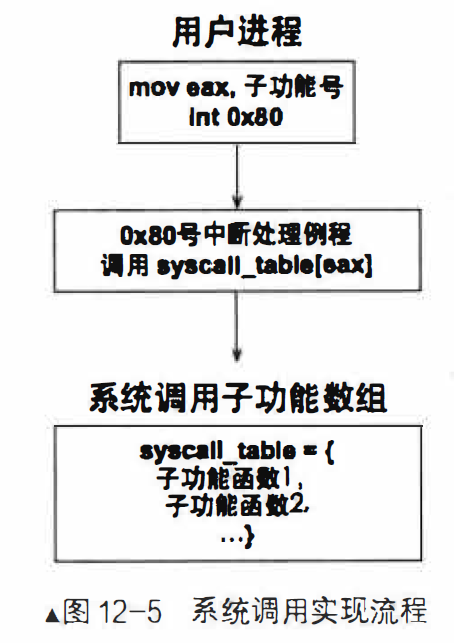
系统调用的实现
系统调用实现框架
一个系统功能调用分为两部分:
- 一部分是暴露给用户进程的接口函数,它属于用户空间,此部分只是用户进程使用系统调用的途径,只负责发需求。
- 另一部分是与之对应的内核具体实现,它属于内核空间,此部分完成的是功能需求,就是我们一直所说的系统调用子功能处理函数。
系统调用实现思路如下:
- 用中断门实现系统调用, 效仿Linux用0x80号中断作为系统调用的入口。
- 在IDT中安装0x80号中断对应的描述符,在该描述符中注册系统调用对应的中断处理例程。
- 建立系统调用子功能表syscall _table, 利用eax寄存器中的子功能号在该表中索引相应的处理函数。
- 用宏实现用户空间系统调用接口_syscall.最大支持3个参数的系统调用, 故只需要完成_syscall[0-3]。 寄存器传递参数,eax为子功能号,ebx保存第1个参数,ecx保存第2个参数,edx保存第3个参数。
增加0x80号中断描述符
处理中断例程的文件有:interrupt.c和kernel.S
kernel/interrupt.c
增改如下内容:
#define IDT_DESC_CNT 0x81 //目前总共支持的中断数量
extern uint32_t syscall_handler(void);
/*初始化中断描述符表*/
static void idt_desc_init(void){
int i, lastindex = IDT_DESC_CNT - 1;
for(i = 0; i < IDT_DESC_CNT; i++){
make_idt_desc(&idt[i], IDT_DESC_ATTR_DPL0, intr_entry_table[i]); //IDT_DESC_DPL0在global.h定义的
}
// 单独处理系统调用,系统调用对应的中断内 DPL 为 3
// 中断处理程序为单独的 syscall_handler
make_idt_desc(&idt[lastindex], IDT_DESC_ATTR_DPL3, syscall_handler);
put_str(" idt_desc_init done\n");
}
声明外部函数syscall_handler,在kernel.S中定义
在idt_desc_init函数中,额外增加0x80号的中断描述符,注册中断例程位syscall_handler,这里要注意指定的DPL是3,因为是要在用户进程中执行int指令来调用该描述符,如果是0则会抛出异常
实现系统调用接口
lib/user/syscall.c
#include "syscall.h"
/* 无参数的系统调用 */
#define _syscall0(NUMBER) ({ \
int retval; \
asm volatile ( \
"int $0x80" \
: "=a" (retval) \
: "a" (NUMBER) \
: "memory" \
); \
retval; \
})
/* 一个参数的系统调用 */
#define _syscall1(NUMBER, ARG1) ({ \
int retval; \
asm volatile ( \
"int $0x80" \
: "=a" (retval) \
: "a" (NUMBER), "b" (ARG1) \
: "memory" \
); \
retval; \
})
/* 两个参数的系统调用 */
#define _syscall2(NUMBER, ARG1, ARG2) ({ \
int retval; \
asm volatile ( \
"int $0x80" \
: "=a" (retval) \
: "a" (NUMBER), "b" (ARG1), "c" (ARG2) \
: "memory" \
); \
retval; \
})
/* 三个参数的系统调用 */
#define _syscall3(NUMBER, ARG1, ARG2, ARG3) ({ \
int retval; \
asm volatile ( \
"int $0x80" \
: "=a" (retval) \
: "a" (NUMBER), "b" (ARG1), "c" (ARG2), "d" (ARG3) \
: "memory" \
); \
retval; \
})
增加 0x80 号中断处理例程
kernel/kernel.S
新增如下内容:
; 0x80 号中断
[bits 32]
extern syscall_table
section .text
global syscall_handler
syscall_handler:
; 1. 保存上下文环境
push 0 ; 压入 0, 使栈中格式统一,占位符
push ds
push es
push fs
push gs
pushad ; PUSHAD 指令压入 32 位寄存器,其入栈顺序是:
; EAX, ECS, EDX, EBX, ESP, EBP, ESI, EDI
push 0x80 ; 此位置压入 0x80 也是为了保持统一的栈格式
; 2. 为系统调用子功能传入参数
push edx ; 系统调用中第 3 个参数
push ecx ; 系统调用中第 2 个参数
push ebx ; 系统调用中第 1 个参数
; 3. 调用子功能处理函数
call [syscall_table + eax * 4]
add esp, 12 ; 跳过上面的 3 个参数
; 4. 将 call 调用后的返回值存入待当前内核栈中 eax 的位置
mov [esp + 8 * 4], eax
jmp intr_exit ; intr_exit 返回, 恢复上下文
syscall_table 是引入外部数据结构,是个数组,用来装填子功能实现函数的地址的,和中断处理函数数组一样
为了复用 intr_exit 从中断退出,这里需要依次入栈寄存器保存上下文环境与之前一样
无论如何都一次性入栈3个参数,虽然会浪费一点栈空间,但是会省事
然后通过索引 syscall_table 数组元素(就是子功能函数地址)进行调用
因为从中断返回用户进程就是从0级栈回到3级栈,而函数调用返回值会存入eax,为了让eax 的值在返回的时候不被覆盖掉,这里直接将eax存入0级栈中保存上下文eax的位置上
此处压入错误码和中断向量号是为了保持格式一致,为什么说 push 0x80 也只是个占位符呢?
我们只用指令int 0x80进行中断之后,CPU 会根据中断向量号 0x80 通过 IDTR 向 IDT 查询门描述符,从门描述符中获取中断处理程序。
而我们的程序中,在初始化 IDT 的时候,已经通过 idt_desc_init 函数创建中断描述符表idt[],在函数中为每一个数组元素都创建了门描述符,门描述符的序号和数组下标一一对应,其中为每一个门描述符都指定了一个中断处理函数,默认情况下就是 Kernel.S 中创建的 intr_entry_table[]数组,和门描述符标号一一对应,其中第 0x80 个门描述符指定的是 syscall_handler 函数,也就是说,无论上述函数中的 push 0x80 填什么内容,都是去执行 syscall_handler 函数,所以 0x80 只是个占位符,但是为了保持格式的同一,就用了 0x80
kernel.S 中的 intr_entry_table[] 数组是个入口程序数组,具体执行的处理程序会通过数组下标索引 idt_table[] 数组,这里面存储的是真正的处理程序,可通过 register_hanlder 进行注册,而我们的系统调用中断使用的是 syscall_table[] 数组进行选择子功能函数。
初始化系统调用和实现sys_getpid
在 IDT 中准备好0x80中断描述符了,增加了中断处理例程,也实现了 _syscall 接口,接下来该实现子功能函数数组了,顺便实现一个系统调用getpid
userprog/syscall-init.c
#include "syscall-init.h"
#include "syscall.h"
#include "stdint.h"
#include "print.h"
#include "thread.h"
#include "console.h"
#include "string.h"
#define syscall_nr 32 // 最大支持的系统子功能调用数
typedef void* syscall;
syscall syscall_table[syscall_nr];
// 返回当前任务的 pid
uint32_t sys_getpid(void) {
return running_thread()->pid;
}
// 初始化系统调用
void syscall_init(void) {
put_str("syscall_init start\n");
syscall_table[SYS_GETPID] = sys_getpid;
put_str("syscall_init done\n");
}
thread/thread.h
给 PCB 结构添加 pid 属性
typedef int16_t pid_t;
...
// 进程或线程的 PCB
struct task_struct {
uint32_t* self_kstack; // 各内核线程都用自己的内核栈
pid_t pid;
enum task_status status;
...
thread/thread.c
增改如下内容:
struct lock pid_lock; // 分配 pid 锁
...
// 分配 pid
static pid_t allocate_pid(void) {
static pid_t next_pid = 0;
lock_acquire(&pid_lock);
next_pid++;
lock_release(&pid_lock);
return next_pid;
}
...
// 初始化线程基本信息
// 待初始化线程指针(PCB),线程名称,线程优先级
void init_thread(struct task_struct* pthread, char* name, int prio) {
memset(pthread, 0, sizeof(*pthread));
pthread->pid = allocate_pid();
strcpy(pthread->name, name);
...
}
// 初始化线程环境
void thread_init(void) {
put_str("thread_init start\n");
list_init(&thread_ready_list);
list_init(&thread_all_list);
lock_init(&pid_lock);
...
首先这里是分配了个 pid 锁,在初始化线程的时候把锁也初始化了
然后创建了个函数allocate_pid()来申请pid,这里用了全局静态变量 next_pid 并赋予了初值为0,每次创建新进程都会+1
在创建线程的时候调用init_thread时,使用allocate_pid来获取一个pid
使用static创建的变量,只会被赋初值1次
添加系统调用 getpid
lib/user/syscall.h
#ifndef __LIB_USER_SYSCALL_H
#define __LIB_USER_SYSCALL_H
#include "stdint.h"
enum SYSCALL_NR { // 用来存放子功能号
SYS_GETPID
};
uint32_t getpid(void);
#endif
lib/user/syacall.c
// 返回当前任务pid
uint32_t getpid() {
return _syscall0(SYS_GETPID);
}
到此,添加用户接口已经完成了
增加系统调用的步骤
-
在syscall.h中的结构enum SYSCALL_ NR里添加新的子功能号。
-
在syscall.c中增加系统调用的用户接口。
-
在syscall-init.c中定义子功能处理函数并在syscall_ table中注册。
在用户进程执行系统调用
kernel/init.c
新增系统调用初始化
syscall_init(); // 初始化系统调用
kernel/main.c
#include "print.h"
#include "init.h"
#include "debug.h"
#include "memory.h"
#include "thread.h"
#include "console.h"
#include "process.h"
#include "syscall-init.h"
#include "syscall.h"
void k_thread_a(void*);
void k_thread_b(void*);
void u_prog_a(void);
void u_prog_b(void);
int prog_a_pid = 0;
int prog_b_pid = 0;
int main(){
put_str("\nI am kernel\n");
init_all();
process_execute(u_prog_a, "user_prog_a");
process_execute(u_prog_b, "user_prog_b");
intr_enable(); // 打开中断, 使时钟中断起作用
console_put_str(" main_pid:0x");
console_put_int(sys_getpid());
console_put_str("\n");
thread_start("k_thread_a",31,k_thread_a,"A_ ");
thread_start("k_thread_b",31,k_thread_b,"B_ ");
while(1);
return 0;
}
void k_thread_a(void* arg){
char* para = arg;
console_put_str(" thread_a_pid:0x");
console_put_int(sys_getpid());
console_put_str("\n");
console_put_str(" prog_a_pid:0x");
console_put_int(prog_a_pid);
console_put_str("\n");
while(1);
}
void k_thread_b(void* arg) {
char* para = arg;
console_put_str(" thread_b_pid:0x");
console_put_int(sys_getpid());
console_put_str("\n");
console_put_str(" prog_b_pid:0x");
console_put_int(prog_b_pid);
console_put_str("\n");
while(1);
}
// 测试用户进程
void u_prog_a(void) {
prog_a_pid = getpid();
while(1);
}
// 测试用户进程
void u_prog_b(void) {
prog_b_pid = getpid();
while(1);
}
运行 Bochs
编译,运行:
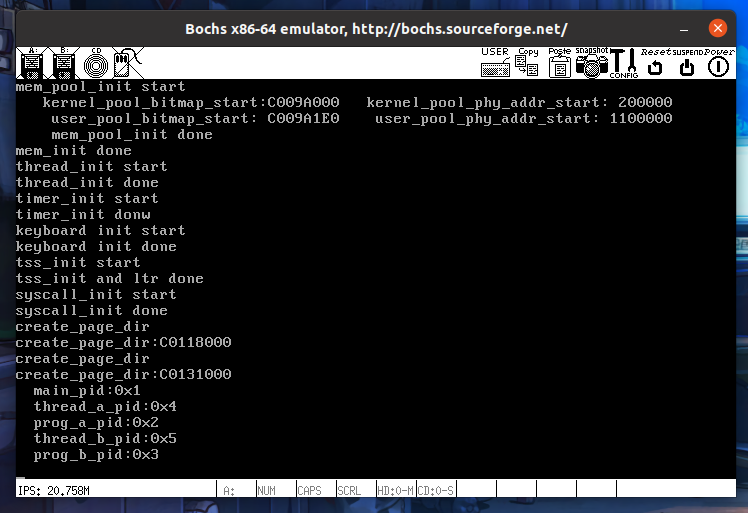
先创建进程再创建线程是为了确保进程能先执行给变量赋值好让线程进行打印输出,运行结果如图:pid与创建的顺序有关
让用户进程“说话”
这里我们要实现自己的printf函数
可变参数的原理
比如printf函数,会根据第一个参数里面的%来判断参数数量,从栈中获取相应数量的参数进行调用执行
Linux 为了方便引用函数中的可变参数,用到了3个宏:
- va_start(ap,v),参数 ap 是用千指向可变参数的指针变量,参数 v 是支待可变参数的函数的第 1 个参数(如对于 printf 来说,参数 v 就是字符串 format)。此宏的功能是使指针 ap 指向 v 的地址,它的调用必须先千其他两个宏,相当于初始化 ap 指针的作用。
- va_arg(ap,t),参数 ap 是用千指向可变参数的指针变量,参数 t 是可变参数的类型,此宏的功能是使指针 ap 指向栈中下一个参数的地址并返回其值。
- va_end(ap),将指向可变参数的变量 ap 置为 null, 也就是清空指针变量 ap。
现在还有点不明白,先往下看
实现系统调用 Write
printf函数里,真正起到格式化作用的是vsprintf,真正起到输出作用的是write系统调用
这里先完成个简易版write系统调用,后面学完文件系统再完善
增加系统调用的三个步骤:
-
在syscall.h中的结构enum SYSCALL_ NR里添加新的子功能号。
-
在syscall.c中增加系统调用的用户接口。
-
在syscall-init.c中定义子功能处理函数并在syscall_ table中注册。
lib/user/syscall.h
#ifndef __LIB_USER_SYSCALL_H
#define __LIB_USER_SYSCALL_H
#include "stdint.h"
enum SYSCALL_NR { // 用来存放子功能号
SYS_GETPID,
SYS_WRITE
};
uint32_t getpid(void);
uint32_t write(char* str);
#endif
lib/user/syscall.c
// 打印字符串str
uint32_t write(char* str) {
return _syscall1(SYS_WRITE, str);
}
userprog/syscall-init.c
// 打印字符串 str (未实现文件系统前的版本)
uint32_t sys_write(char* str) {
console_put_str(str);
return strlen(str);
}
// 初始化系统调用
void syscall_init(void) {
put_str("syscall_init start\n");
syscall_table[SYS_GETPID] = sys_getpid;
syscall_table[SYS_WRITE] = sys_write;
前面提到,无论如何 int 0x80 中断后,都会调用 syscall_table 进行中断处理,通过 eax 里的子功能号来索引 syscall_table数组,获取相应的处理函数
这个syscall_table数组在syscall-init.c里的syscall_init函数中被初始化,数组索引用作功能描述的枚举类型,位于syscall.h里,对应索引号的函数位于syscall.c里面
所以只需要在 syscall.h 里添加新的功能到枚举类型里,然后将相应的处理函数加到 syscall.c 里,然后通过 syscall-init.c 的初始化函数进行初始化,即可实现新增系统调用
实现 printf
printf是vsprintf和write的封装,write已经实现了,这里要实现vsprintf
函数的功能是将format字符串中的%用实际参数值代替,变成一个新的字符串,返回字符串的长度
lib/stdio.c
#include "stdio.h"
#include "interrupt.h"
#include "global.h"
#include "string.h"
#include "syscall.h"
#include "print.h"
#define va_start(ap, v) ap = (va_list)&v // 把ap指向第一个固定参数v
#define va_arg(ap, t) *((t*)(ap += 4)) // ap指向下一个参数并返回其值
#define va_end(ap) ap = NULL // 清除ap
/* 将整型转换成字符(integer to ascii) */
static void itoa(uint32_t value, char** buf_ptr_addr, uint8_t base) {
uint32_t m = value % base; // 求模,最先掉下来的是最低位
uint32_t i = value / base; // 取整
if (i) { // 如果倍数不为0则递归调用。
itoa(i, buf_ptr_addr, base);
}
if (m < 10) { // 如果余数是0~9
*((*buf_ptr_addr)++) = m + '0'; // 将数字0~9转换为字符'0'~'9'
} else { // 否则余数是A~F
*((*buf_ptr_addr)++) = m - 10 + 'A'; // 将数字A~F转换为字符'A'~'F'
}
}
/* 将参数ap按照格式format输出到字符串str,并返回替换后str长度 */
uint32_t vsprintf(char* str, const char* format, va_list ap) {
char* buf_ptr = str;
const char* index_ptr = format;
char index_char = *index_ptr;
int32_t arg_int;
while(index_char) {
if (index_char != '%') {
*(buf_ptr++) = index_char;
index_char = *(++index_ptr);
continue;
}
index_char = *(++index_ptr); // 得到%后面的字符
switch(index_char) {
case 'x':
arg_int = va_arg(ap, int);
itoa(arg_int, &buf_ptr, 16);
index_char = *(++index_ptr); // 跳过格式字符并更新index_char
break;
}
}
return strlen(str);
}
/* 格式化输出字符串format */
uint32_t printf(const char* format, ...) {
va_list args;
va_start(args, format); // 使args指向format
char buf[1024] = {0}; // 用于存储拼接后的字符串
vsprintf(buf, format, args);
va_end(args);
return write(buf);
}
itoa 函数将数字进行进制转换并转换成字符串
vsprintf 函数将指针参数单独用变量存起来,然后通过对变量的操作,逐字符判断是不是%,如果是就判断下一位是什么类型,根据类型,进行不同的操作,这里目前仅支持x,也就是hex类型的参数
printf 函数通过 vsprintf 获取到拼接后的字符串,通过write进行输出
kernel/main.c
// 测试用户进程
void u_prog_a(void) {
printf(" prog_a_pid:%x\n",getpid());
while(1);
}
// 测试用户进程
void u_prog_b(void) {
printf(" prog_b_pid:%x\n",getpid());
while(1);
}
将用户进程的输出方式进行修改,让用户进程自己输出
运行 Bochs
编译,运行:
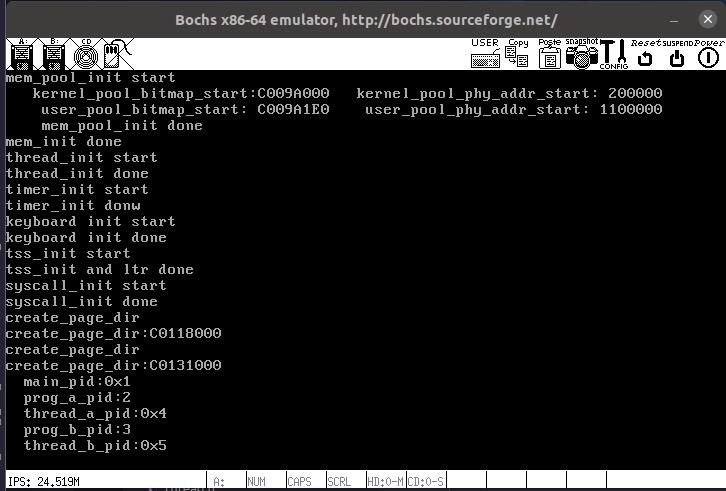
成功实现用户系统调用控制台输出
完善 printf
lib/stdio.c
/* 将参数ap按照格式format输出到字符串str,并返回替换后str长度 */
uint32_t vsprintf(char* str, const char* format, va_list ap) {
char* buf_ptr = str;
const char* index_ptr = format;
char index_char = *index_ptr;
int32_t arg_int;
char* arg_str;
while(index_char) {
if (index_char != '%') {
*(buf_ptr++) = index_char;
index_char = *(++index_ptr);
continue;
}
index_char = *(++index_ptr); // 得到%后面的字符
switch(index_char) {
case 's':
arg_str = va_arg(ap, char*);
strcpy(buf_ptr, arg_str);
buf_ptr += strlen(arg_str);
index_char = *(++index_ptr);
break;
case 'c':
*(buf_ptr++) = va_arg(ap, char);
index_char = *(++index_ptr);
break;
case 'd':
arg_int = va_arg(ap, int);
// 若是负数, 将其转为正数后,再正数前面输出个负号'-'.
if (arg_int < 0) {
arg_int = 0 - arg_int;
*buf_ptr++ = '-';
}
itoa(arg_int, &buf_ptr, 10);
index_char = *(++index_ptr);
break;
case 'x':
arg_int = va_arg(ap, int);
itoa(arg_int, &buf_ptr, 16);
index_char = *(++index_ptr); // 跳过格式字符并更新index_char
break;
}
}
return strlen(str);
}
// 同printf不同的地方就是字符串不是写到终端,而是写到buf中
uint32_t sprintf(char* buf, const char* format, ...) {
va_list args;
uint32_t retval;
va_start(args, format);
retval = vsprintf(buf, format, args);
va_end(args);
return retval;
}
完善堆的内存管理
malloc 底层原理
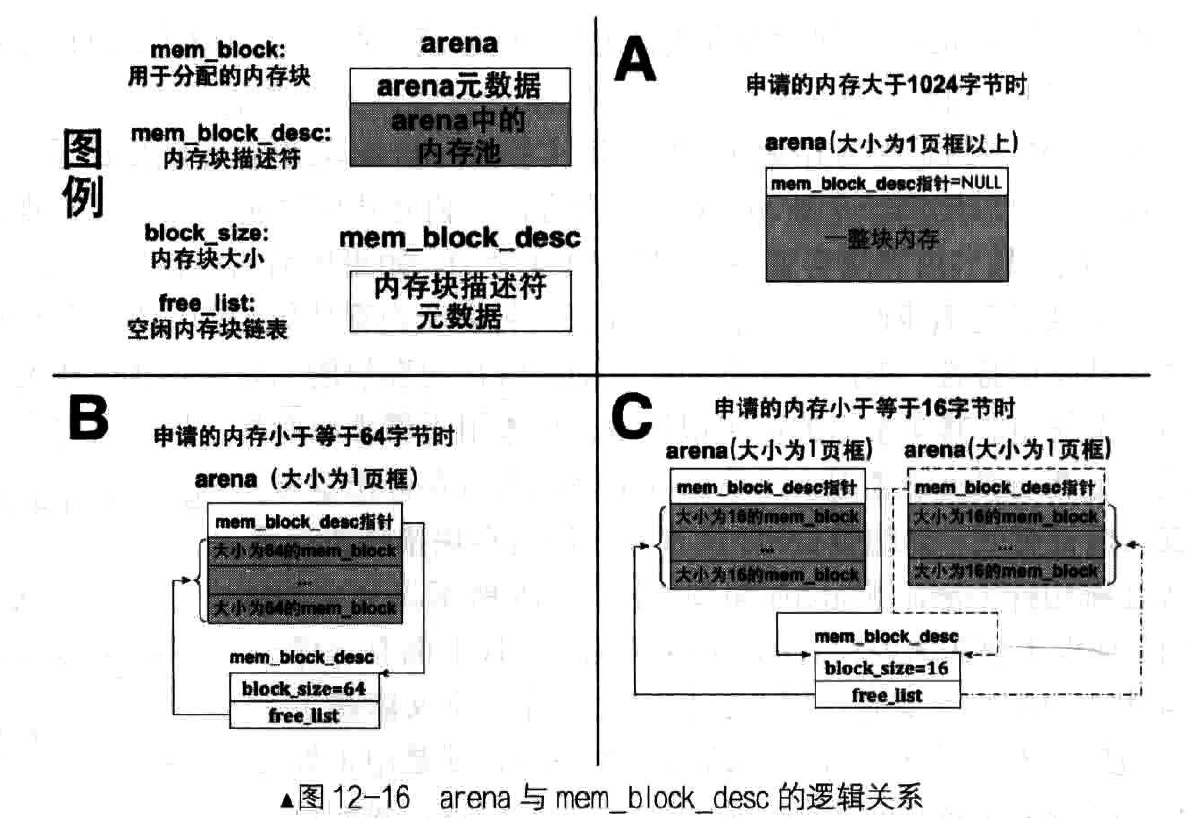
在内存管理系统中,arena为任意大小内存的分配提供了统一的接口,它既支待1024字节以下的小块内存的分配,又支持大千1024字节以上的大块内存
malloc函数实际上就是通过arena申请这些内存块。arena 是个内存仓库,并不直接对外提供内存分配,只有内存块描述符才对外提供内存块,内存块描述符将同类arena中的空闲内存块汇聚到 一起,作为某一规格内存块的分配入口。
因此,内存块描述符 与arena是一对多的关系,每个arena都要与唯一的内存块描述符关联起来,多个同一规格的arena为同一 规格的内存块描述符供应内存块,它们各自的元信息中用内存块描述符指针指向同一个内存块描述符。现在把整个逻辑贯穿起来, 如图所示:
底层初始化
原来以页为单位进行内存分配,现在要以arena为单位进行分配,需要做一些准备工作:
kernel/memory.h
// 内存块
struct mem_block {
struct list_elem free_elem;
};
// 内存块描述符
struct mem_block_desc {
uint32_t block_size; // 内存块大小
uint32_t blocks_per_arena; // 本 arena 中可容纳此 mem_block 的数量
struct list free_list; // 目前可用的 mem_block 链表
};
#define DESC_CNT 7 // 内存块描述符个数
内存块描述符:16,32,64,128,256,512,1024,这7类
kernel/memory.c
增改如下内容:
// 内存仓库 arena 元信息
struct arena {
struct mem_block_desc* desc;
// large 为 true 时, cnt 表示的是页框数
// 否则 cnt 表示空闲 mem_block 数量
uint32_t cnt;
bool large;
};
struct mem_block_desc k_block_descs[DESC_CNT]; // 内核内存块描述符数组
void block_desc_init(struct mem_block_desc* desc_array) {
uint16_t desc_idx, block_size = 16;
// 初始化每个 mem_block_desc 描述符
for (desc_idx = 0; desc_idx < DESC_CNT; desc_idx++) {
desc_array[desc_idx].block_size = block_size;
// 初始化 arena 中的内存块数量
desc_array[desc_idx].blocks_per_arena = (PG_SIZE - sizeof(struct arena)) / block_size;
list_init(&desc_array[desc_idx].free_list);
block_size *= 2; // 更新为下一个规格内存块
}
}
//内存管理部分初始化入口
void mem_init(){
put_str("mem_init start\n");
uint32_t mem_bytes_total = (*(uint32_t*)(0xb00));
put_str("mem_bytes_total: 0x"); put_int(mem_bytes_total);put_str("\n");
mem_pool_init(mem_bytes_total);
// 初始化 mem_block_desc 数组 descs, 为 malloc 做准备
block_desc_init(k_block_descs);
put_str("mem_init done\n");
}
这里定义了 arena 的元信息,每一个arena的内存块描述符只能指向自己大小所对应的内存块描述符
经过 block_desc_init 函数将内存块描述符的 block_size, block_per_arena 和 free_list 进行初始化,block_size 的初始值是 16,每次循环乘以2,填充完整个内存块描述符数组
通过mem_init函数进行调用,对内核内存块描述符数组进行初始化
实现 sys_malloc
thread/thread.h
// 进程或线程的 PCB
struct task_struct {
uint32_t* self_kstack; // 各内核线程都用自己的内核栈
pid_t pid;
...
struct virtual_addr userprog_vaddr; // 用户进程的虚拟地址
struct mem_block_desc u_block_desc[DESC_CNT]; //用户进程内存块描述符
uint32_t stack_magic; // 栈的边界标记, 用于检测栈的溢出
};
PCB结构添加用户进程内存块描述符成员
userprog/process.c
/* 创建用户进程 */
void process_execute(void* filename, char* name) {
...
thread->pgdir = create_page_dir();
block_desc_init(thread->u_block_desc);
创建用户进程的时候,初始化进程的内存块描述符
kernel/memory.c
// 返回 arena 中第 idx 个内存块的地址
static struct mem_block* arena2block(struct arena* a, uint32_t idx) {
return (struct mem_block*)((uint32_t)a + sizeof(struct arena) + idx * a->desc->block_size);
}
// 返回内存块 b 所在的 arena 地址
static struct arena* block2arena(struct mem_block* b) {
return (struct arena*)((uint32_t)b & 0xfffff000);
}
先定义2个arena和mem_block相互转换的函数
arena2block 函数原理是在arena所指的的页框中,跳过元信息部分,再用idx乘以arena中内存块的大小,最后的地址便是arena中第idx个内存块的首地址
block2arena 函数用于将 7 种类型的内存块转换为内存块所在的arena,由于此类内存块所在的arena占据完整的1页,所以前20位是一样的
// 在堆中申请 size 字节内存
void* sys_malloc(uint32_t size) {
enum pool_flags PF;
struct pool* mem_pool;
uint32_t pool_size;
struct mem_block_desc* descs;
struct task_struct* cur_thread = running_thread();
// 判断用哪个内存池
if (cur_thread->pgdir == NULL) { // 若为内核线程
PF = PF_KERNEL;
pool_size = kernel_pool.pool_size;
mem_pool = &kernel_pool;
descs = k_block_descs;
} else { // 用户进程 pcb 中的 pgdir 会在为其分配页表时创建
PF = PF_USER;
pool_size = user_pool.pool_size;
mem_pool = &user_pool;
descs = cur_thread->u_block_desc;
}
// 若申请的内存不在内存池容量范围内则直接返回 NULL
if (!(size > 0 && size < pool_size)) {
return NULL;
}
struct arena* a;
struct mem_block* b;
lock_acquire(&mem_pool->lock);
// 超过最大内存块 1024, 就分配页框
if (size > 1024) {
uint32_t page_cnt = DIV_ROUND_UP(size + sizeof(struct arena), PG_SIZE);
a = malloc_page(PF, page_cnt);
if (a != NULL) {
memset(a, 0, page_cnt*PG_SIZE); // 将分配的内存清零
// 对于分配的大块页框, 将 desc 置为 NULL, cnt 置为页框数, large 置为 true
a->desc = NULL;
a->cnt = page_cnt;
a->large = true;
lock_release(&mem_pool->lock);
return (void*)(a + 1); // 跨过 arena 大小, 把剩下的内存返回
} else {
lock_release(&mem_pool->lock);
return NULL;
}
} else { // 若申请的内存小于等于 1024, 可在各种规格的 mem_block_desc 中去适配
uint8_t desc_idx;
// 从内存块描述符中匹配合适的内存块规格
for (desc_idx = 0; desc_idx < DESC_CNT; desc_idx++) {
if (size <= descs[desc_idx].block_size) { // 从小往大, 找到后退出
break;
}
}
// 若 mem_block_desc 的 free_list 中已经没有可用的 mem_block
// 就创建新的 arena 提供 mem_block
if (list_empty(&descs[desc_idx].free_list)) {
a = malloc_page(PF, 1);
if (a == NULL) {
lock_release(&mem_pool->lock);
return NULL;
}
memset(a, 0, PG_SIZE);
// 对于分配的小块内存, 将 desc 置为相应内存块描述符
// cnt 置为 arena 可用的内存块数, large 置为 false
a->desc = &descs[desc_idx];
a->large = false;
a->cnt = descs[desc_idx].blocks_per_arena;
uint32_t block_idx;
enum intr_status old_status = intr_disable();
// 开始将 arena 拆分成内存块, 并添加到内存块描述符的 free_list 中
for (block_idx = 0; block_idx < descs[desc_idx].blocks_per_arena; block_idx++) {
b = arena2block(a, block_idx);
ASSERT(!elem_find(&a->desc->free_list, &b->free_elem));
list_append(&a->desc->free_list, &b->free_elem);
}
intr_set_status(old_status);
}
// 开始分配内存块
b = elem2entry(struct mem_block, free_elem, list_pop(&(descs[desc_idx].free_list)));
memset(b, 0, descs[desc_idx].block_size);
a = block2arena(b); // 获取内存块 b 所在的 arena
a->cnt--; // 将此 arena 中的空闲块数减 1
lock_release(&mem_pool->lock);
return (void*)b;
}
}
测试
kernel/main.c
void k_thread_a(void*);
void k_thread_b(void*);
int main(){
put_str("\nI am kernel\n");
init_all();
thread_start("k_thread_a",31,k_thread_a,"A_ ");
thread_start("k_thread_b",31,k_thread_b,"B_ ");
intr_enable(); // 打开中断, 使时钟中断起作用
while(1);
return 0;
}
void k_thread_a(void* arg){
char* para = arg;
void* addr = sys_malloc(33);
printf(" I am thread_a, sys_malloc(33),addr is 0x%x\n",(int)addr);
while(1);
}
void k_thread_b(void* arg) {
char* para = arg;
void* addr = sys_malloc(63);
printf(" I am thread_b, sys_malloc(63),addr is 0x%x\n",(int)addr);
while(1);
}
运行 Bochs
编译,运行:
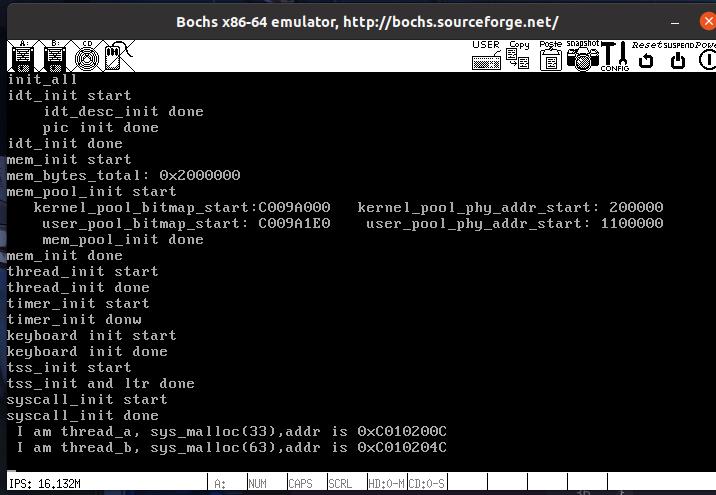
线程 a 获得的内存地址是0xc0102000,arena元信息占0xc大小,64字节是 0x40大小
因为申请的都是同一个arena的内存块,所以他们之间差0x40
内存的释放
分配内存的步骤:
- 申请虚拟地址
- 申请物理地址
- 将虚拟地址和物理地址进行映射
以上3个步骤封装在了malloc_page中
释放内存和分配内存步骤相反:
- 在物理地址池中释放物理页地址, 相关的函数是pfree, 操作的位图同palloc。
- 在页表中去掉虚拟地址的映射, 原理是将虚拟地址对应 pte的P位置 0,相关的函数是page_table_pte_remove。
- 在虚拟地址池中释放虚拟地址, 相关的函数是vaddr_remove,操作的位图同vaddr_get。
我们将以上三个功能封装到函数mfree_page中。
为什么是把pte的P位置零?
因为CPU检测到 pte 的 p 位是 0 ,就会认为该pte无效
kernel/memory.c
// 将物理地址 pg_phy_addr 回收到物理内存池
void pfree(uint32_t pg_phy_addr) {
struct pool* mem_pool;
uint32_t bit_idx = 0;
if (pg_phy_addr >= user_pool.phy_addr_start) { // 用户物理内存池
mem_pool = &user_pool;
bit_idx = (pg_phy_addr - user_pool.phy_addr_start) / PG_SIZE;
} else { // 内核内存池
mem_pool = &kernel_pool;
bit_idx = (pg_phy_addr - kernel_pool.phy_addr_start) / PG_SIZE;
}
bitmap_set(&mem_pool->pool_bitmap, bit_idx, 0); // 将位图中该位清 0
}
// 去掉页表中虚拟地址 vaddr 的映射, 只去掉 vaddr 对应的 pte
static void page_table_pte_remove(uint32_t vaddr) {
uint32_t* pte = pte_ptr(vaddr);
*pte &= ~PG_P_1; // 将页表项 pte 的 P 位置 0
asm volatile ("invlpg %0" : : "m" (vaddr) : "memory"); // 更新 tlb
}
// 在虚拟地址池中释放以 vaddr 起始的连续 pg_cnt 个虚拟页地址
static void vaddr_remove(enum pool_flags pf, void* _vaddr, uint32_t pg_cnt) {
uint32_t bit_idx_start = 0, vaddr = (uint32_t)_vaddr, cnt = 0;
if (pf == PF_KERNEL) { // 内核虚拟内存池
bit_idx_start = (vaddr - kernel_vaddr.vaddr_start) / PG_SIZE;
while (cnt < pg_cnt) {
bitmap_set(&kernel_vaddr.vaddr_bitmap, bit_idx_start+cnt++, 0);
}
} else { // 用户虚拟内存池
struct task_struct* cur_thread = running_thread();
bit_idx_start = (vaddr - cur_thread->userprog_vaddr.vaddr_start) / PG_SIZE;
while (cnt < pg_cnt) {
bitmap_set(&cur_thread->userprog_vaddr.vaddr_bitmap, bit_idx_start+cnt++, 0);
}
}
}
pfree 函数,将pg_phy_addr回收,也就是回收1个物理页,先判断属于哪个内存池,然后该页在该内存池的位图索引,将该位置零
page_table_pte_remove 函数,获取到该虚拟地址的pte,然后将P位置零,使用内联汇编刷新快表tlb
vaddr_remove 函数, 在虚拟地址池中释放以 vaddr 起始的连续 pg_cnt 个虚拟页地址
3个步骤相关的函数已经齐了,接下来该封装到一起了:
// 释放以虚拟地址 vaddr 为起始的 cnt 个物理页框
void mfree_page(enum pool_flags pf, void* _vaddr, uint32_t pg_cnt) {
uint32_t pg_phy_addr;
uint32_t vaddr = (int32_t)_vaddr, page_cnt = 0;
ASSERT((pg_cnt >= 1) && (vaddr % PG_SIZE) == 0);
pg_phy_addr = addr_v2p(vaddr); // 获取虚拟地址 vaddr 对应的物理地址
// 确保待释放的物理内存在低端 1MB+1KB 大小的页目录 + 1KB 大小的页表地址外
ASSERT((pg_phy_addr % PG_SIZE) == 0 && pg_phy_addr >= 0x102000);
// 判断 pg_phy_addr 属于用户物理内存池还是内核物理内存池
if (pg_phy_addr >= user_pool.phy_addr_start) { // 位于用户物理内存池
vaddr -= PG_SIZE;
while (page_cnt < pg_cnt) {
vaddr += PG_SIZE;
pg_phy_addr = addr_v2p(vaddr);
// 确保物理地址属于用户物理地址池
ASSERT((pg_phy_addr % PG_SIZE) == 0 && pg_phy_addr >= user_pool.phy_addr_start);
// 先将对应的物理页框归还到内存池
pfree(pg_phy_addr);
// 再从页表中清楚此虚拟地址所在的页表项 pte
page_table_pte_remove(vaddr);
page_cnt++;
}
// 清空虚拟地址的位图中的相应位
vaddr_remove(pf, _vaddr, pg_cnt);
} else { // 位于内核物理内存池
vaddr -= PG_SIZE;
while (page_cnt < pg_cnt) {
vaddr += PG_SIZE;
pg_phy_addr = addr_v2p(vaddr);
// 确保待释放的物理内存只属于内核物理地址池
ASSERT((pg_phy_addr % PG_SIZE) == 0 && \
pg_phy_addr >= kernel_pool.phy_addr_start && \
pg_phy_addr < user_pool.phy_addr_start);
// 先将对应的物理页框归还到内存池
pfree(pg_phy_addr);
// 再从页表中清除此虚拟地址所在的页表框 pte
page_table_pte_remove(vaddr);
page_cnt++;
}
// 清空虚拟地址的位图中的相应位
vaddr_remove(pf, _vaddr, pg_cnt);
}
}
mfree_page 函数:释放以虚拟地址 vaddr 为起始的 cnt 个物理页框,就是之前3个函数的封装很好理解
实现 sys_free
sys_free是内存释放的统一接口, 无论是页框级别的内存和小的内存块, 都统一用sys_free 处理。 因此,sys_free 针对这两种内存的处理有各自的方法:
- 大内存的处理称之为“释放”,就是把页框在虚拟内存池和物理内存池的位图中将相应位置0。
- 小内存的处理称之为“回收“,是将arena中的内存块重新放回到内存块描述符中的空闲块链表 free_list。
kernel/memory.c
// 回收内存 ptr
void sys_free(void* ptr) {
ASSERT(ptr != NULL);
if (ptr != NULL) {
enum pool_flags PF;
struct pool* mem_pool;
// 判断是线程, 还是进程
if (running_thread()->pgdir == NULL) {
ASSERT((uint32_t)ptr >= K_HEAP_START);
PF = PF_KERNEL;
mem_pool = &kernel_pool;
} else {
PF = PF_USER;
mem_pool = &user_pool;
}
lock_acquire(&mem_pool->lock);
struct mem_block* b = ptr;
struct arena* a = block2arena(b); // 把 mem_block 转换成 arena, 获取元信息
ASSERT(a->large == 0 || a->large == 1);
if (a->desc == NULL && a->large ==true) { // 大于 1024 的内存
mfree_page(PF, a, a->cnt);
} else { // 小于等于 1024 的内存块
// 先将内存块回收到 free_list
list_append(&a->desc->free_list, &b->free_elem);
// 再判断此 arena 中的内存块是否都是空闲, 如果是就释放 arena
if (++a->cnt == a->desc->blocks_per_arena) {
uint32_t block_idx;
for (block_idx = 0; block_idx < a->desc->blocks_per_arena; block_idx++) {
struct mem_block* b = arena2block(a, block_idx);
ASSERT(elem_find(&a->desc->free_list, &b->free_elem));
list_remove(&b->free_elem);
}
mfree_page(PF, a, 1);
}
}
lock_release(&mem_pool->lock);
}
}
测试
kernel/main.c
void k_thread_a(void*);
int main(){
put_str("\nI am kernel\n");
init_all();
thread_start("k_thread_a",31,k_thread_a,"A_ ");
intr_enable(); // 打开中断, 使时钟中断起作用
while(1);
return 0;
}
void k_thread_a(void* arg){
char* para = arg;
void* addr1;
void* addr2;
void* addr3;
void* addr4;
console_put_str("thread_a_start\n");
int max = 100;
while(max-- > 0){
int size = 128;
addr1 = sys_malloc(size);
size *= 2;
addr2 = sys_malloc(size);
size *= 2;
addr3 = sys_malloc(size);
size *= 8;
addr4 = sys_malloc(size);
sys_free(addr1);
sys_free(addr2);
sys_free(addr4);
sys_free(addr3);
}
console_put_str("thread_a_end\n");
while(1);
}
这里简化了书上的暴力测试,只用了一个线程
通过查看内存池位图来进行测试运行结果
运行 Bochs
编译,运行:
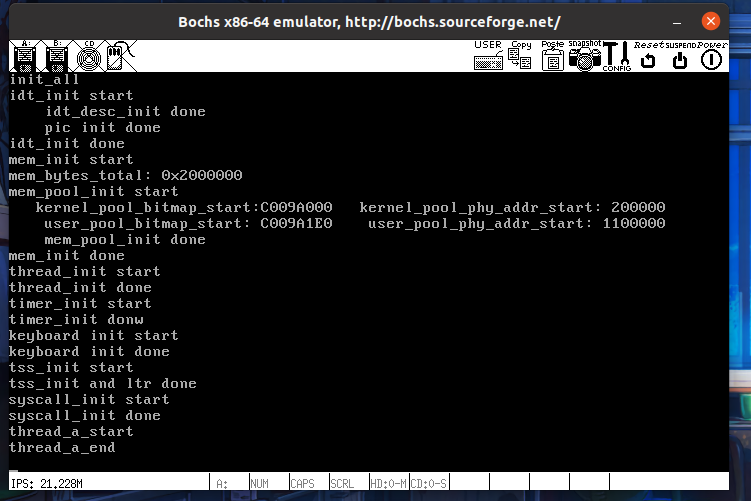
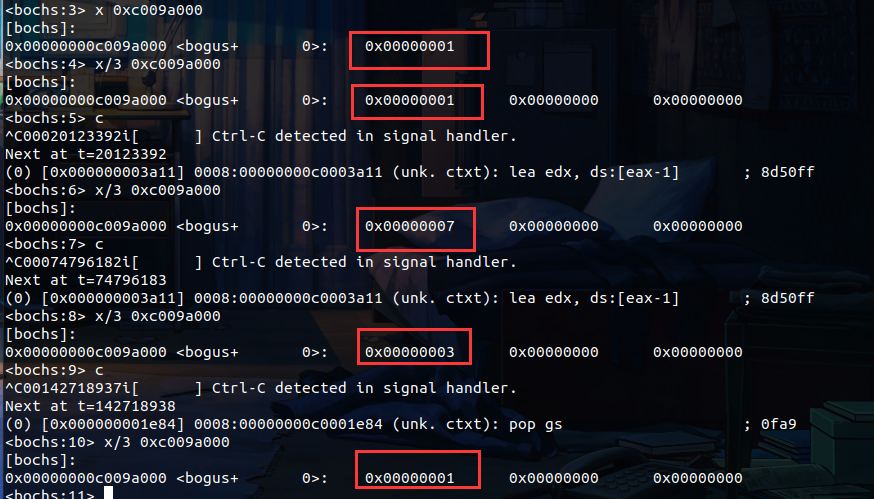
从刚开始执行,到执行结束,中间位图有所变化,但最后都释放成功,变回原状
实现系统调用 malloc 和 free
lib/user/syscall.h
#ifndef __LIB_USER_SYSCALL_H
#define __LIB_USER_SYSCALL_H
#include "stdint.h"
enum SYSCALL_NR { // 用来存放子功能号
SYS_GETPID,
SYS_WRITE,
SYS_MALLOC,
SYS_FREE
};
uint32_t getpid(void);
uint32_t write(char* str);
void* malloc(uint32_t size);
void free(void* ptr);
#endif
lib/user/syscall.c
// 申请 size 字节大小的内存, 并返回结果
void* malloc(uint32_t size) {
return (void*)_syscall1(SYS_MALLOC, size);
}
// 释放 ptr 指向的内存
void free(void* ptr) {
_syscall1(SYS_FREE, ptr);
}
userprog/syscall-init.c
// 初始化系统调用
void syscall_init(void) {
put_str("syscall_init start\n");
syscall_table[SYS_GETPID] = sys_getpid;
syscall_table[SYS_WRITE] = sys_write;
syscall_table[SYS_MALLOC] = sys_malloc;
syscall_table[SYS_FREE] = sys_free;
put_str("syscall_init done\n");
}
kernel/main.c
void k_thread_a(void*);
void k_thread_b(void*);
void u_prog_a(void);
void u_prog_b(void);
int main(void) {
put_str("I am kernel\n");
init_all();
intr_enable(); // 打开中断
process_execute(u_prog_a, "u_prog_a");
process_execute(u_prog_b, "u_prog_b");
thread_start("k_thread_a", 31, k_thread_a, "I am thread_a");
thread_start("k_thread_b", 31, k_thread_b, "I am thread_b");
while(1);
return 0;
}
/* 在线程中运行的函数 */
void k_thread_a(void* arg) {
void* addr1 = sys_malloc(256);
void* addr2 = sys_malloc(255);
void* addr3 = sys_malloc(254);
console_put_str(" thread_a malloc addr:0x");
console_put_int((int)addr1);
console_put_char(',');
console_put_int((int)addr2);
console_put_char(',');
console_put_int((int)addr3);
console_put_char('\n');
int cpu_delay = 100000;
while(cpu_delay-- > 0);
sys_free(addr1);
sys_free(addr2);
sys_free(addr3);
while(1);
}
/* 在线程中运行的函数 */
void k_thread_b(void* arg) {
void* addr1 = sys_malloc(256);
void* addr2 = sys_malloc(255);
void* addr3 = sys_malloc(254);
console_put_str(" thread_b malloc addr:0x");
console_put_int((int)addr1);
console_put_char(',');
console_put_int((int)addr2);
console_put_char(',');
console_put_int((int)addr3);
console_put_char('\n');
int cpu_delay = 100000;
while(cpu_delay-- > 0);
sys_free(addr1);
sys_free(addr2);
sys_free(addr3);
while(1);
}
void u_prog_a(void) {
void* addr1 = malloc(256);
void* addr2 = malloc(255);
void* addr3 = malloc(254);
printf(" prog_a malloc addr:0x%x, 0x%x, 0x%x\n", (int)addr1, (int)addr2, (int)addr3);
int cpu_delay = 100000;
while(cpu_delay-- > 0);
free(addr1);
free(addr2);
free(addr3);
while(1);
}
void u_prog_b(void) {
void* addr1 = malloc(256);
void* addr2 = malloc(255);
void* addr3 = malloc(254);
printf(" prog_b malloc addr:0x%x, 0x%x, 0x%x\n", (int)addr1, (int)addr2, (int)addr3);
int cpu_delay = 100000;
while(cpu_delay-- > 0);
free(addr1);
free(addr2);
free(addr3);
while(1);
}
运行 Bochs
编译,运行:
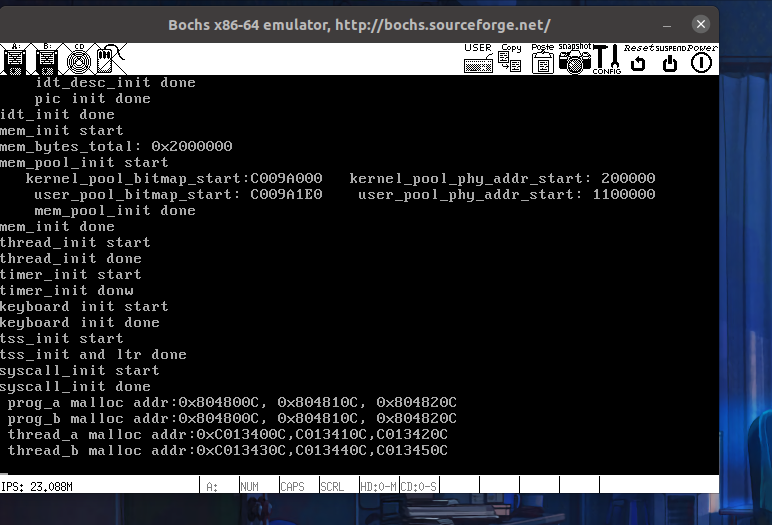
内核线程虚拟地址必须唯一,所以虚拟地址出现了累加现象
用户进程独享内存空间,所以申请到的地址都是一样的
实验成功!
本篇总结
本篇回顾了系统中断原理和执行流程,使用系统中断实现了系统调用,并实现了printf函数和完善了内存管理系统实现了malloc和free系统调用
本篇的讲解中,我们把内存进一步进行了划分,原本以页为单位进行分配空间,现在将小于页大小的内存,分配成内存块,一共有7类内存块,由arena管理,当我们需要少量内存时,通过arena来分配/回收内存块。
malloc和free是一个大的封装,在这两个系统调用里进行判断需要的内存是大的还是小的,来选择使用页还是内存块来进行分配
参考资料
- 《操作系统真象还原》Chapter 12